Using an input set of queries, Data Virtualization recommends a ranked list of data
caches that can improve the performance of the input queries and potentially help future query
workloads.
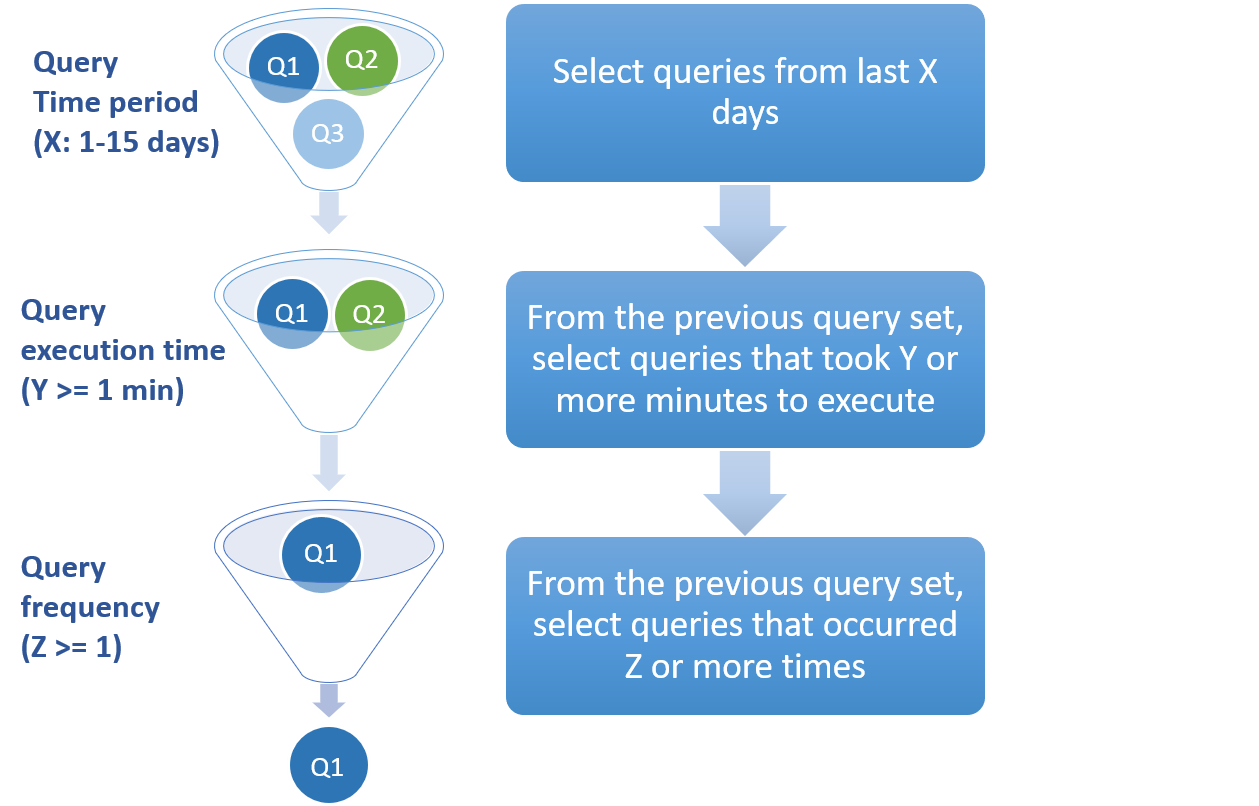
The input queries are queries that were run anywhere in the previous 1 day up to the previous 15
days, and must have an execution time of at least one minute. The recommendations are considered
valid for 1 day after which they can change as the query workload changes.
The cache recommendation engine uses two models to generate recommendations.
The rule-based model uses sophisticated heuristics to determine which cache candidates help the
input query workload.
The machine learning based model uses a pre-trained machine learning model that detects
underlying query patterns and predicts caches that help a potential future query workload.
Both models produce a ranked list of cache candidates that are consolidated by the engine to
generate a final set of recommendations. You can choose to enable or disable machine learning based
cache recommendations. By default, machine learning based cache recommendations are
enabled.
In addition to cache creation recommendations, the engine also recommends cache
disable and delete recommendations based on past usage and other metrics. These recommendations
appear in the Active and Inactive caches tab for
existing caches.
Machine learning based cache recommendations consider underlying query patterns and predict
caches that are valid for 1 day.
Data Virtualization uses a pre-trained model that was trained on
an industry standard data
set.
You can choose to enable or disable
machine learning based cache recommendations.
The recommendation engine consolidates and ranks the final set of recommendations from both
models. The Manager can then add data caches from these
recommendations.
Data Virtualization provides an engine to generate a ranked list of recommendations. The ranking
of cache creation recommendations is determined by the execution time of queries, the frequency of
those queries in the input workload, and the weight of the two models. The engine is fully aware and
does not recommend the creation of caches that exist. Additionally, the engine does not recommend
the creation of duplicated caches.
The process of generating cache recommendations consists of five stages, as depicted in the
following image:
Figure 1. Cache recommendation process overview
Collect
The recommendation engine selects a set of customer's queries whose performance needs to be
enhanced and for whom caches might be recommended. The cache recommendation engine collects
information such as query text, execution time, cardinality, timestamp, and frequency for the
provided time period.
The following image shows how queries from historical workload are filtered
to arrive to the final input set of queries for the recommendation engine:Figure 2. Collection stage in the cache recommendation process.
Cache configuration settings are defined by the Data VirtualizationManager, see Configure cache recommendations for details.
Extract
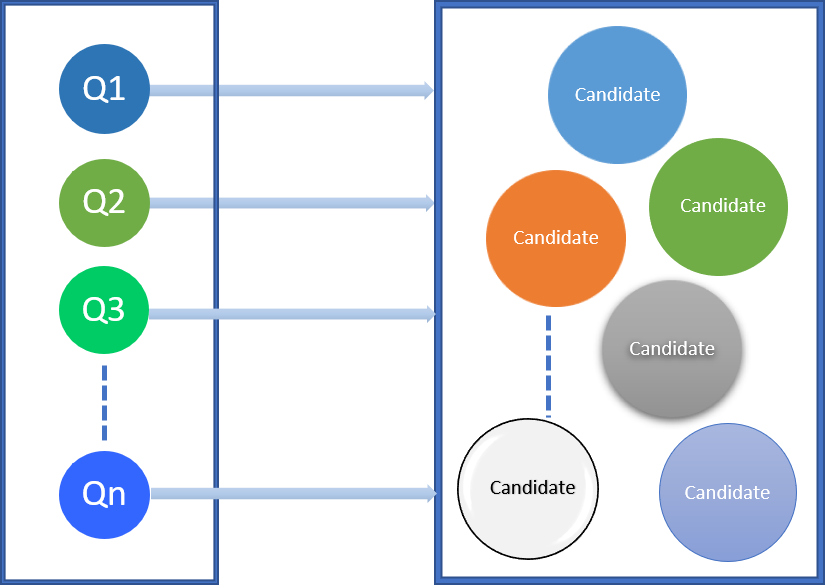
The recommendation engine generates potential cache candidates for the input query
workload.
Translate
The recommendation engine converts and consolidates the candidates to ensure that they are
syntactically and semantically correct, unique, and pass all Db2 restrictions.
Evaluate
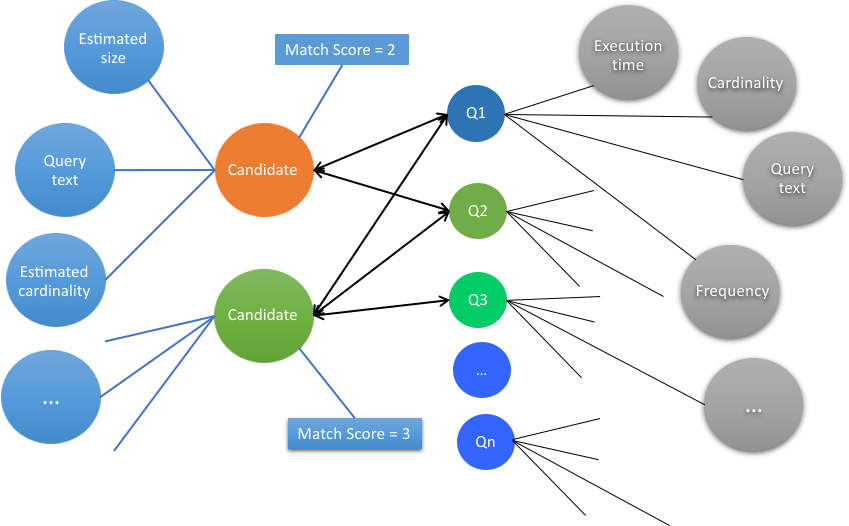
The engine evaluates the converted definitions by matching each cache candidate against the
input query workload to determine their effectiveness, rank and sort. Also, for scoring the machine
learning model, a high-dimensional feature vector is created for each candidate. Figure 3. Evaluation stage in the cache recommendation process.
As a result of this evaluation, the recommendation engine generates a match
score for each cache candidate. The evaluation of each candidate is based on the following criteria.
Matchability: Number of queries that match the cache candidate.
Diversity: Different queries that match the cache candidate.
Cardinality: Size of result set that the cache candidate fetched.
Performance: Execution time of queries that the cache candidate
matched.
Rank and sort
The recommendation engine ranks and sorts the cache candidates to generate a final list of
recommendations. The final list of recommendations is created based on the following criteria.
Sort candidates by using a weighted metric of matched query execution time and frequency.
Any tie between candidates is broken by using query frequency and cardinality.
Figure 4. Ranking and sorting stage in the cache recommendation
process.
Was the topic helpful?
0/1000
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Focus sentinel
Cloud Pak for Data relationship map
Use this interactive map to learn about the relationships between your tasks, the tools you need, the services that provide the tools, and where you use the tools.
Select any task, tool, service, or workspace
You'll learn what you need, how to get it, and where to use it.
Tasks you'll do
Some tasks have a choice of tools and services.
Tools you'll use
Some tools perform the same tasks but have different features and levels of automation.
Create a notebook in which you run Python, R, or Scala code to prepare, visualize, and analyze data, or build a model.
Automatically analyze your tabular data and generate candidate model pipelines customized for your predictive modeling problem.
Create a visual flow that uses modeling algorithms to prepare data and build and train a model, using a guided approach to machine learning that doesn’t require coding.
Create and manage scenarios to find the best solution to your optimization problem by comparing different combinations of your model, data, and solutions.
Create a flow of ordered operations to cleanse and shape data. Visualize data to identify problems and discover insights.
Automate the model lifecycle, including preparing data, training models, and creating deployments.
Work with R notebooks and scripts in an integrated development environment.
Create a federated learning experiment to train a common model on a set of remote data sources. Share training results without sharing data.
Deploy and run your data science and AI solutions in a test or production environment.
Find and share your data and other assets.
Import asset metadata from a connection into a project or a catalog.
Enrich imported asset metadata with business context, data profiling, and quality assessment.
Measure and monitor the quality of your data.
Create and run masking flows to prepare copies of data assets that are masked by advanced data protection rules.
Create your business vocabulary to enrich assets and rules to protect data.
Track data movement and usage for transparency and determining data accuracy.
Track AI models from request to production.
Create a flow with a set of connectors and stages to transform and integrate data. Provide enriched and tailored information for your enterprise.
Create a virtual table to segment or combine data from one or more tables.
Measure outcomes from your AI models and help ensure the fairness, explainability, and compliance of all your models.
Replicate data to target systems with low latency, transactional integrity and optimized data capture.
Consolidate data from the disparate sources that fuel your business and establish a single, trusted, 360-degree view of your customers.
Services you can use
Services add features and tools to the platform.
Develop powerful AI solutions with an integrated collaborative studio and industry-standard APIs and SDKs. Formerly known as Watson Studio.
Quickly build, run and manage generative AI and machine learning applications with built-in performance and scalability. Formerly known as Watson Machine Learning.
Discover, profile, catalog, and share trusted data in your organization.
Create ETL and data pipeline services for real-time, micro-batch, and batch data orchestration.
View, access, manipulate, and analyze your data without moving it.
Monitor your AI models for bias, fairness, and trust with added transparency on how your AI models make decisions.
Provide efficient change data capture and near real-time data delivery with transactional integrity.
Improve trust in AI pipelines by identifying duplicate records and providing reliable data about your customers, suppliers, or partners.
Increase data pipeline transparency so you can determine data accuracy throughout your models and systems.
Where you'll work
Collaborative workspaces contain tools for specific tasks.
Where you work with data.
> Projects > View all projects
Where you find and share assets.
> Catalogs > View all catalogs
Where you deploy and run assets that are ready for testing or production.
> Deployments
Where you manage governance artifacts.
> Governance > Categories
Where you virtualize data.
> Data > Data virtualization
Where you consolidate data into a 360 degree view.

 As a result of this evaluation, the recommendation engine generates a match score for each cache candidate. The evaluation of each candidate is based on the following criteria.
As a result of this evaluation, the recommendation engine generates a match score for each cache candidate. The evaluation of each candidate is based on the following criteria.